Modernization.
Faster, smarter, better for business.
LeapLogic uses the power of automation to transform data warehouses, ETL, Hadoop, and analytics systems, end-to-end, to cloud-native stacks

![]() Databricks Migration Partner of
the Year 2023
Databricks Migration Partner of
the Year 2023
![]() Stevie Awards Gold Winner for the
Most Innovative Tech Company 2023
Stevie Awards Gold Winner for the
Most Innovative Tech Company 2023
![]() Cloud Stratus Awards - Top Cloud
Company 2023
Cloud Stratus Awards - Top Cloud
Company 2023
/1
Liberate tech architecture with LeapLogic
A traditional approach to modernization will get the job done—but the status quo requires substantial time commitments at a high risk of human error.
LeapLogic eliminates unpredictable variables while transforming both legacy logic and code, bringing cloud benefits to businesses with more accuracy and less disruption.
+

Leap to the cloud
Migrate legacy ETL, data warehouse, Hadoop, and analytics system to any cloud environment with up to 95% automation using LeapLogic

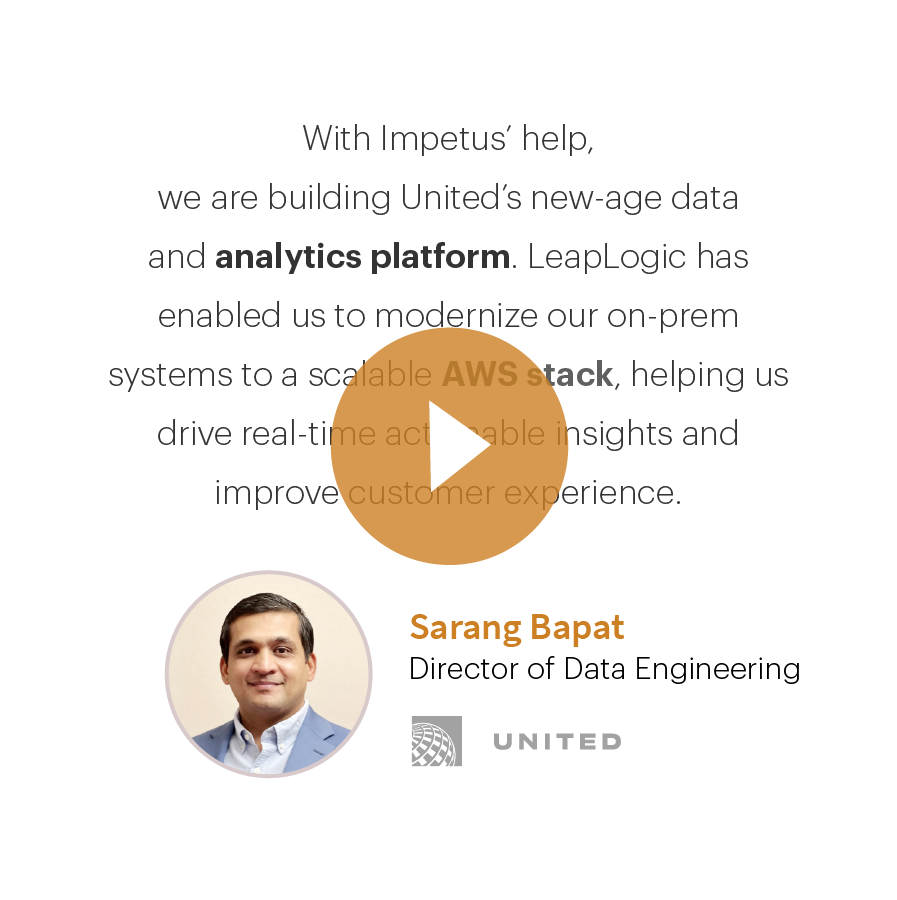
Customer Perspective
United Airlines’ Director of Data Engineering talks about their legacy data stack modernization journey with LeapLogic

/2
Leave fears behind and accelerate your business into its next digital era
Results only LeapLOGIC can offer:
Compared to traditional approaches
+
4x
faster
1.5x
faster


2x
lower
2x
less


100%
compliant
100%
SLAs met

/2
Leave fears behind and accelerate your business into its next digital era
Results only LeapLOGIC can offer:
Compared to traditional approaches
+
4x
faster
1.5x
faster
2x
lower
2x
less
100%
compliant
100%
SLAs met

Your migration, made possible
No matter where you’re going—or where you’re coming from—LeapLogic can support your transformation journey



















Your migration, made possible
No matter where you’re going—or where you’re coming from—LeapLogic can support your transformation journey



























These are exactly the automation processes we need to ensure what we roll out has been engineered for the highest reliability. Our customers will thank you for it. Great job!
airline
In the past 6 months, your team has managed to do what the others before you couldn’t do in a full year. The collaboration, accountability, and dedication to delivering a quality product are remarkable. Your team has turned our vision into reality. Can’t thank you enough!
