Step 3
Migrating Confluent topics to Amazon MSK
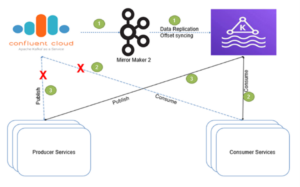
Using MirrorMaker 2.0 (MM2), we migrated Confluent Kafka clusters to Amazon MSK. The tool uses a Kafka consumer to consume messages from the source Confluent Kafka cluster and re-publishes them to the target Amazon MSK cluster, thereby eliminating any downtime. Migrating involved the following steps:
1. Setting up MM2 cluster on EC2 instance
- Configured MM2 on EC2 instance
- Configured source Confluent Kafka and target Amazon MSK cluster details in MM2 configuration properties file.
A sample properties file is given below:
#Apache Kafka clusters
clusters = #comma separated list of Apache Kafka cluster aliases
source.bootstrap.servers = :9092
target.bootstrap.servers = :9092
source -> target.enabled = true
Source and target cluster configuration
source.config.storage.replication.factor = 1
target.config.storage.replication.factor = 1
source.offset.storage.replication.factor = 1
target.offset.storage.replication.factor = 1
Mirror Maker configuration
offset-sync.topoc.replication.factor = 1
heartbeat.topic.replication.factor = 1
checkpoint.topic.replication.factor = 1
topics = .*
groups = .*
tasks.max = 1
replication.factor = 1
refresh.topics.enabled = true
sync.topic.configs.enabled = true
Enable heartbeats and checkpoints
source->target.emit.heartbeats.enabled = true
source->target.emit.checkpoints.enabled = true
2. Replicating Kafka topics on the target environment
Next, we extracted the existing topics from the source Confluent Kafka cluster. A sample command used is given below:
bin/kafka-topics –describe –zookeeper <ZooKeeper_Url> | grep ReplicationFactor | awk ‘{print “/opt/confluent/confluent-5.5.1/bin/kafka-topics –create –bootstrap-server <Broker_Url> –topic ” $1 ” –replication-factor ” $2 ” –partitions ” $3 ” –config ” $4}’ >> ./create_topic_list
Example:
bin/kafka-topics –describe –zookeeper zkp-1.int.dev:2181, zkp-2.int.dev:2181, zkp-3.int.dev:2181/env/kafka | grep ReplicationFactor | awk ‘{print”/opt/confluent/confluent-5.5.1/bin/kafka-topics –create –bootstrap-server 10.3.20.61:9092 –topic ” $1 ” –replication-factor ” $2 ” –partitions ” $3 ” –config ” $4}’ >> ./create_topic_list
Broker_Url is the target cluster broker URL, and create_topic_list will have all the topic creation commands ready for the target cluster.
The configuration parameters used are given below:
- $1: List of topics name we wanted to extract
- $2: Replication factor in the target Amazon MSK cluster
- $3: # of partitions we wanted to create in target Amazon MSK cluster
- $4: Configuration details of the target Amazon MSK cluster
Based on the above command, a sample output data is given below:
../../confluent-5.5.1/bin/kafka-topics –create –zookeeper z-1.kafka.us-east-1.amazonaws.com:2181,z-3.kafka.us-east-1.amazonaws.com:2181,z-2.kafka.us-east-1.amazonaws.com:2181 –topic <topic_name> –replication-factor 3 –partitions 1 –config min.insync.replicas=1 follower.replication.throttled.replicas=*
../../confluent-5.5.1/bin/kafka-topics –create –zookeeper z-1.kafka.us-east-1.amazonaws.com:2181,z-3.kafka.us-east-1.amazonaws.com:2181,z-2.kafka.us-east-1.amazonaws.com:2181 –topic <topic_name> –replication-factor 2 –partitions 1 –config min.insync.replicas=1 follower.replication.throttled.replicas=*
../../confluent-5.5.1/bin/kafka-topics –create –zookeeper z-1.kafka.us-east-1.amazonaws.com:2181,z-3.kafka.us-east-1.amazonaws.com:2181,z-2.kafka.us-east-1.amazonaws.com:2181 –topic <topic_name> –replication-factor 3 –partitions 1 –config min.insync.replicas=1
3. Creating topics in Amazon MSK
Create topics in Amazon MSK using command in create_topic_list file that are created in the previous step.