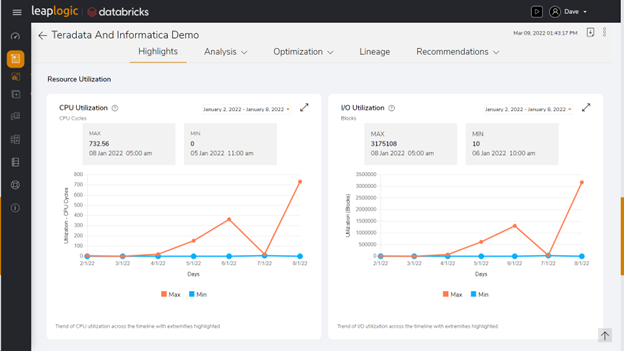
A Lakehouse is a new-age, open architecture that combines the best components of data lakes and data warehouses, enabling enterprises to power a wide range of analytics use cases – from business intelligence (BI) to artificial intelligence (AI).
The Databricks Lakehouse Platform simplifies data architecture, breaks down data silos, and provides a single source of truth for analytics, data science, and machine learning (ML).
While data lakes excel at processing massive amounts of data at low cost, the Databricks Lakehouse addresses data reliability and ease-of-use constraints by adding data warehousing capabilities like:
- ACID compliance
- Schema enforcement and governance
- Open collaboration
- Support for diverse types of workloads
- Fine-grained security
- Update/delete/merge functionality
- Extensive ANSI SQL support
- A super-fast BI querying engine
The platform also provides native integration with MLflow – an open source platform for managing the end-to-end machine learning lifecycle.
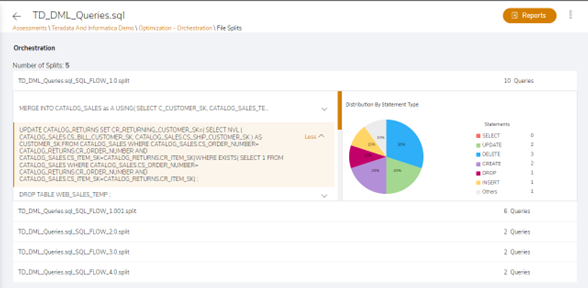
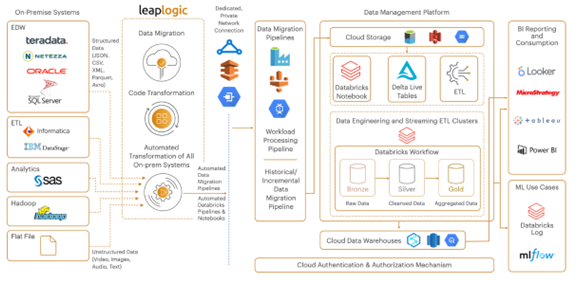
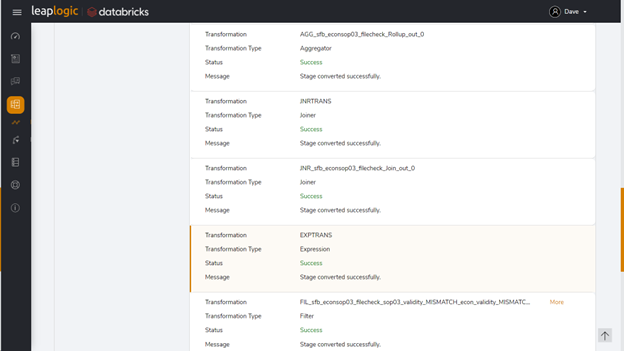
LeapLogic, a cloud transformation accelerator, helps enterprises modernize legacy data warehouses, ETL, SAS, and Hadoop workloads to the Databricks Lakehouse. This blog discusses the best practices for ensuring a seamless transformation journey with LeapLogic.