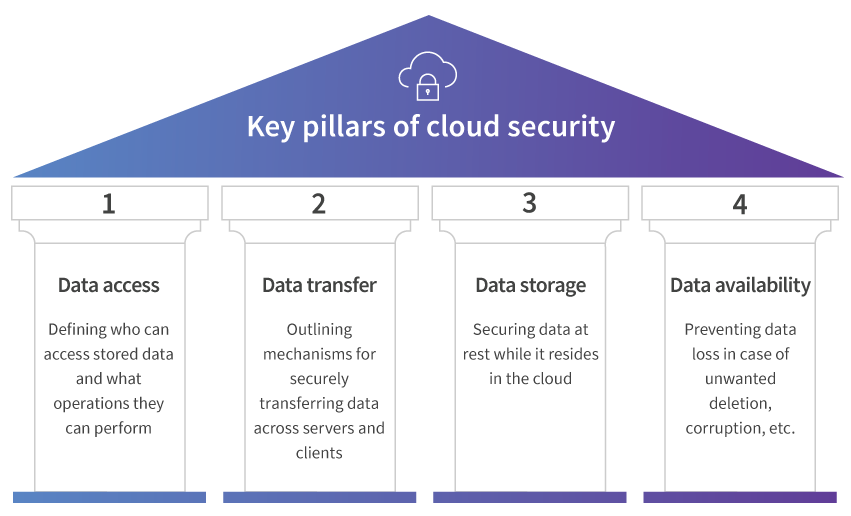
Data-driven decision-making is a key driver for enterprises in their digital transformation journey. Businesses are now switching to scalable, unified data storage repositories like enterprise data lakes, built on cloud storage options such as Amazon Simple Storage Service (S3), Google Cloud Storage, Azure Data Lake Storage (ADLS), and Azure Blob Storage. But while the cloud offers unmatched speed, flexibility, and cost savings, security remains a major concern. This blog delves into the key pillars of cloud security and outlines how a holistic approach can help enterprises protect the confidentiality, integrity, and availability of their data.