Snowflake is a popular cloud data warehouse choice for scalability, agility, cost-effectiveness, and a comprehensive range of data integration tools. Enterprises prefer Snowflake for features like continuous bulk loading/unloading, data protection, secure data sharing, standard and extended SQL support, a broad range of connectors and drivers, and support for syncing and replicating databases.
At Impetus Technologies, we have extensive experience helping large-scale companies seamlessly migrate legacy data lakes to the cloud. This article details how we have helped a US-based Fortune Global 500 healthcare service provider migrate to a high performant, scalable cloud-based data lake to minimize cost and data ingestion time.
The healthcare service provider was facing the following challenges with legacy data processing pipelines:
- Managing hardware infrastructure – Spin up servers, batch ETL job orchestration, outages and downtime, integration of tools to ingest, organize, pre-process, and query data stored in the lake
- High maintenance costs – Capital expenses like servers and storage disks, operating expenses like IT and engineering costs
- Limited scalability – Manual addition and configuration of servers, monitoring resource utilization, and maintenance of additional servers
To address these challenges, we proposed migrating the legacy data platform to a cloud-based solution built on Snowflake that would:
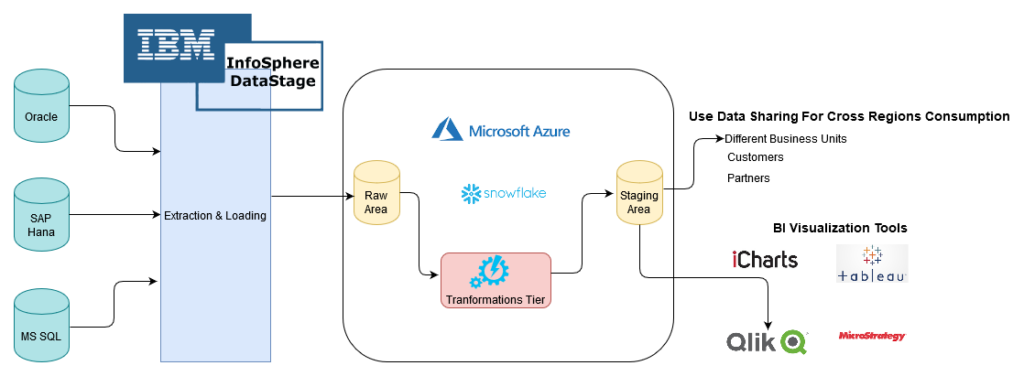
- Support data ingestion from a variety of relational databases like Oracle, MS SQL, and SAP Hana using IBM InfoSphere DataStage (ETL jobs)
- Cleanse and prepare raw data using Snowflake SQL
- Store data on Snowflake storage
- Orchestrate, schedule, and monitor batch ETL jobs using IBM Tivoli Workload Automation
- Integrate IBM Tivoli Workload Scheduler with Remedy Incident Management System for sending email notifications for failures
Here are the details of the application architecture on Snowflake: