How does it work??
GANs are a deep-learning-based generative model and have two sub-models:
- The generator model, which we train to generate new examples
- The discriminator model, which classifies examples as real (from the domain) or fake (generated)
The two models are trained together in the following way:
- The generator generates perfect replicas from the input domain every time
- The discriminator successfully identifies real and fake samples
When the generator fools the discriminator, it is rewarded, or no change is needed to the model parameters, but the discriminator is penalized, and its model parameters are updated.
GAN model architecture
Let’s deep dive into the GAN architecture:
The Discriminator
The task of the discriminator is to identify between real and fake data. To become proficient, it is trained on two data inputs —
- The generator-produced data (which we can call as fake)
- The given data (which we can label as real)
Let’s say the generator synthesized (fake) data is labelled as ‘0’ and the real data is labelled as ‘1’. The discriminator then processes this data, predicting either a ‘0’ or ‘1’ on the examples it sees.
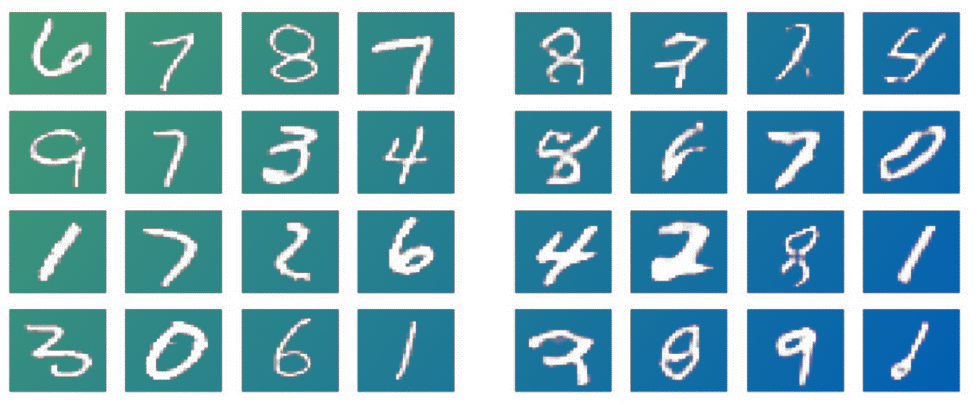
Real images of numbers | Fake images of numbers
As in the above example, the discriminator needs to become good at correctly identifying the right group as the fake numbers and the left group as the real ones.
More technically, the discriminator will return the probability that a given example is a real example. If this probability is above a certain threshold (for example, 0.5), the discriminator will determine the example to be real and return 1. Otherwise, the discriminator will return 0.
Note that training a discriminator is a supervised learning task. We explicitly provide target labels as ‘0′ and ‘1’ to the discriminator.
The Generator
The generator network takes random data as input (mathematically, we can think of it as an n-dimensional vector derived from a latent space) and transforms this data to generate examples that can fool the discriminator.
The performance of the generator depends upon the quality of the discriminator. Hence, training the generator is more complicated. Thus, the generator must be trained after the discriminator. Once the training starts, the output of the generator (synthesized data) is passed on as input to the discriminator, which attempts to classify the synthesized data as fake or real.
The generator just wants to fool the discriminator, and the discriminator wants to identify the fake data point from the real one clearly.