
Challenges
A US-based healthcare software and services provider wanted to create an alternate Azure IaaS platform to replicate their existing data model from an on-premises SQL Server. Their current SQL server was choking with large volumes of data. It was unable to serve data in the cloud to facilitate predictive analytics and machine learning (ML) for analyzing use cases in near-real-time. Moreover, it could not easily scale to accommodate sudden spurts in processing capacity.
To address these challenges, the client wanted an IaaS platform on Azure to help:
- Reduce data storage, management, and operational costs
- Improve scalability
- Migrate historical and incremental data
- Reduce the time taken to develop new data pipelines
- Facilitate complex analytics
- Enable BI

35% reduction in data platform operational cost across use cases
Solution
Responsible for architecture, design, development, and DevOps of the platform, the Impetus team adopted a multi-phased step-by-step approach to create the IaaS platform on Azure.
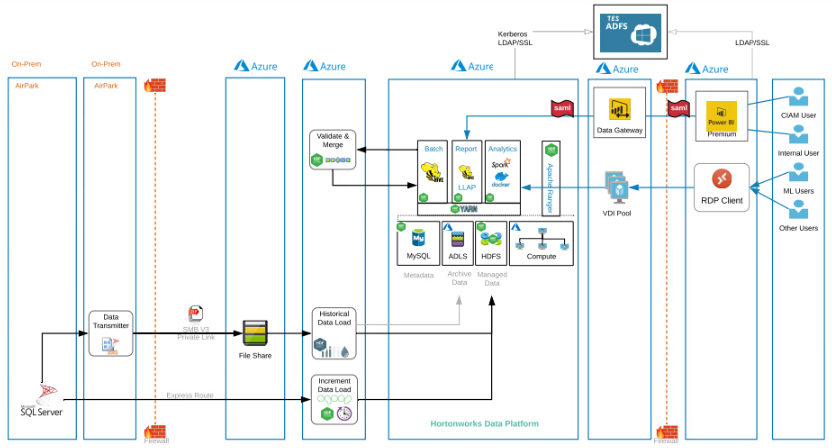
The solution used Hortonworks Data Platform (HDP) on Azure with 1 Ambari node, 3 Master nodes, 8 Data nodes, 3 Edge nodes, 2 MySQL nodes, Azure File Share, and Azure Data Lake Storage (ADLS) Gen2 for data storage and archival with 48 TB HDFS space.
For historical data migration of around 10 TB data from File Share to ADLS Gen2, HDP was leveraged, while incremental data of 2.5 GB daily was migrated from SQL Server to ADLS Gen2 using Apache Sqoop.
A diagrammatic representation of the solution is given below:
Highlights
- Set up HDP and HDF on Azure virtual machines to operationalize the platform with the required tool stack in one framework
- Used Apache NiFi and Apache Oozie for managing data pipeline workflows, which reduced the overall development and cost effort
- Used Apache Hive for data processing and Hive LLAP for data analytics and extraction. SQL-like Hive query structure helped the team to develop ETL scripts for around 170 tables. Hive facilitated data management in a schema-like on-premises SQL server, minimizing the effort required to change, test, and deploy the affected Hive scripts.
- Replaced the existing SAP BO with Power BI for interactive reporting, which enabled the team to create a visually appealing analytical dashboard for client managers.
- Encrypted Azure Blob Storage and volumes for security and HIPAA compliance to safeguard PHI information with custom key encryption
- Configured Power BI dashboards to provide access to specific workspaces within the organization
- Used MS Azure ExpressRoute to extend the on-premises network to the cloud over a private connection, which enabled the team to query and synchronize data in the cloud with on-premises data within 24 hours while adhering to the compliance guidelines
3x faster operationalization of new data pipelines
Impact
The solution also enabled complex data analytics and ML data modeling on claims data in the cloud by exposing an API for efficiently querying and retrieving data in the cloud. By ensuring independent scalability of computing and storage, the client could reduce data platform operational costs by 35% across all use cases. It also facilitated the operationalization of new data pipelines 3x faster, leveraging the platform’s out-of-the-box processes and components.
Business Benefits
- Operationalize Power BI reporting for clients
- Meet the desired data availability SLA of 24 hours post-processing the monthly transaction data on SQL Server
- Increase data availability to 99.9999999999% (12 9’s) over a given year
- Reduce data storage and management cost by 50%









